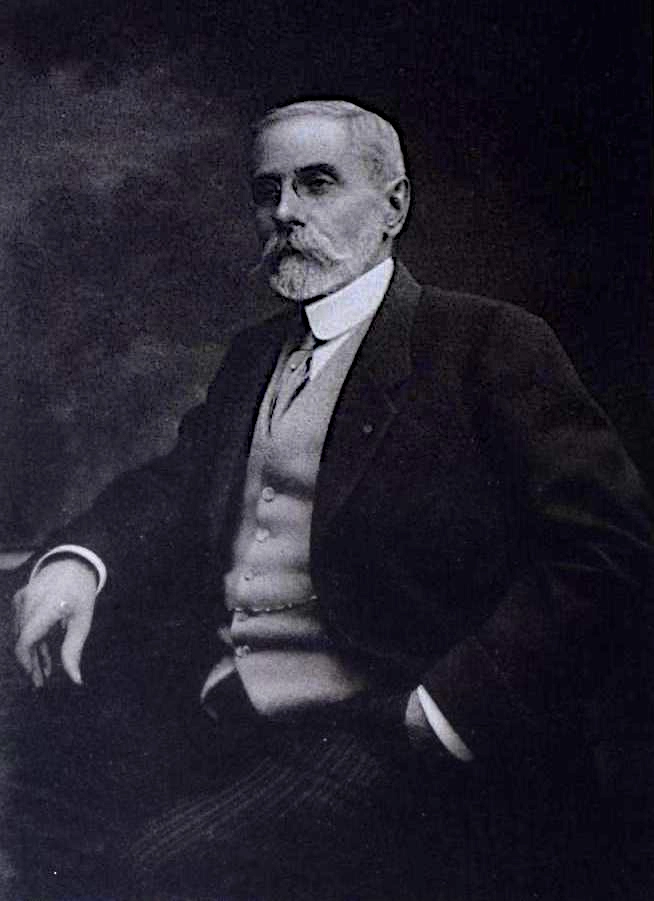Bolívar y Ponte, Simon le « Libérateur » de la Colombie, né à Caracas le 25 juillet 1783, mort à San Pedro, près de Santa Marta, le 17 décembre 1830.
Il était issu de l’une des « familias Mantuanas » qui à l’époque de la domination espagnole, constituaient la noblesse créole du Venezuela. Selon la coutume des Américains fortunés de l’époque, il fut envoyé en Europe alors qu’il n’avait que quatorze ans.
D’Espagne, il passa en France, et résida quelques années à Paris. Il se maria à Madrid en 1802, et retourna ensuite au Venezuela, où sa femme mourut subitement de la fièvre jaune.
Puis, il visita l’Europe une seconde fois, et assista au couronnement impérial de Napoléon en 1804, et à son accession à la couronne de fer de Lombardie en 1805.
En 1809, il revint dans son pays natal, et en dépit des exhortations de José Felix Rivas, son cousin, il refusa de se joindre à la révolution qui éclata le 19 avril 1810 à Caracas ; mais, après cet événement, il accepta une mission à Londres pour acheter des armes et solliciter la protection du gouvernement britannique.
Il fut apparemment bien reçu par le Marquis de Wellesley, alors secrétaire aux Affaires étrangères, mais n’obtint rien sinon l’autorisation d’exporter des armes contre argent comptant, moyennant le paiement de lourds droits de douane.
A son retour de Londres, il se retira à nouveau de la vie publique, jusqu’en septembre 1811, lorsque le général Miranda, alors commandant en chef des forces terrestres et maritimes des insurgés, le décida à accepter le grade de lieutenant-colonel dans l’état-major, et le commandement de Puerto Cabello, la plus puissante forteresse du Venezuela.
Les prisonniers de guerre espagnols que Miranda envoyait régulièrement à Puerto Cabello pour être enfermés dans la citadelle réussirent à triompher par surprise de leurs gardiens et à s’emparer de la citadelle : bien qu’ils fussent sans armes, alors que lui-même disposait d’une nombreuse garnison et d’importantes réserves de munitions, Bolívar s’embarqua précipitamment pendant la nuit avec huit de ses officiers, sans en informer ses propres troupes ; arrivé à l’aube à La Guayra, il se retira dans la propriété de San Mateo.
Lorsqu’elle comprit que son commandement avait fui, la garnison quitta la place en bon ordre, et la forteresse fut immédiatement occupée par les Espagnols sous les ordres de Monteverde.
Cet événement fit pencher la balance en faveur de l’Espagne et obligea Miranda, sur un ordre du Congrès, à signer, le 26 juillet 1812, le traité de Vittoria, qui replaça le Venezuela sous l’autorité de l’Espagne.
Le 30 juillet, Miranda arriva à La Guayra où il avait l’intention d’embarquer à bord d’un navire anglais.
Lorsqu’il rendit visite au commandant de la place, le colonel Manuel Maria Casas, il rencontra toute une nombreuse compagnie, dont Don Miguel Peňa et Simón Bolívar qui le persuada de passer au moins une nuit dans la maison de Casas.
A deux heures du matin, alors que Miranda dormait profondément, Casas, Peňa et Bolívar entrèrent dans sa chambre avec quatre soldats armés, s’emparèrent prudemment de son épée et de son pistolet, puis l’éveillèrent, lui dirent sans ménagement de se lever et de s’habiller, le mirent aux fers, et le livrèrent finalement à Monteverde, qui l’envoya à Cadix où il mourut enchaîné, après quelques années de captivité.
Cet acte, commis sous le prétexte que Miranda avait trahi son pays en capitulant à Vitoria, procura à Bolívar la faveur toute particulière de Monteverde ; quand Bolívar lui demanda son passeport, il déclara que « la requête du colonel Bolívar devait être satisfaite, en récompense du service rendu au Roi d’Espagne en livrant Miranda ».
Bolívar fut ainsi autorisé à s’embarquer pour Curaçao où il passa six semaines ; il se dirigea ensuite, en compagnie de son cousin Rivas, vers la petite république de Carthagène, où un grand nombre de soldats qui avaient servi sous les ordres du général Miranda s’étaient réfugiés.
Rivas leur proposa d’entreprendre une expédition contre les Espagnols au Venezuela, avec Bolívar comme commandant en chef.
Ils acceptèrent la première proposition avec enthousiasme ; ils s’opposèrent à la seconde, mais finirent par céder, à condition que Rivas devint commandant adjoint.
Manuel Rodriguez Torrices, président de la république de Carthagène, ajouta aux trois cents soldats ainsi enrôlés sous les ordres de Bolívar cinq cents hommes sous le commandement de son cousin, Manuel Castillo. L’expédition commença en début de janvier 1813.
Des dissensions s’élevèrent entre Bolívar et Castillo quant au commandement suprême, et Castillo leva soudain le camp avec ses grenadiers.
Bolívar, pour sa part, se proposait de suivre son exemple et de retourner à Carthagène, mais Rivas réussit finalement à le persuader de poursuivre sa route au moins jusqu’à Bogotá, où se tenait le congrès de Nouvelle-Grenade.
Ils furent bien reçus : le congrès les aida de toutes les façons possibles et les éleva tous deux au grade de général ; après avoir divisé leur petite armée, ils marchèrent sur Caracas par des itinéraires différents.
Plus ils avançaient, plus ils reçurent des renforts ; les cruautés commises par les Espagnols agirent partout comme des sergents recruteurs pour l’armée de l’indépendance.
La capacité de résistance des Espagnols fut brisée, en partie parce que leur armée se trouvait être composée au trois quarts d’indigènes qui, à chaque combat, couraient rejoindre les rangs ennemis, et en partie en raison de la lâcheté de généraux tels que Tiscar, Cagigal et Fierro, qui désertaient leurs propres troupes à chaque occasion.
C’est ainsi qu’un simple jeune homme, Santiago Mariňo réussit à déloger les Espagnols des provinces de l’Ouest.
La seule résistance sérieuse de la part des Espagnols fut dirigée contre la colonne de Rivas, qui battit cependant le général Monteverde à Lostaguanes, et le força à s’enfermer dans Puerto Cabello avec le reste de ses troupes.
A la nouvelle de l’arrivée de Bolívar, le général Fierro, gouverneur de Caracas, envoya des émissaires pour proposer une capitulation, qui fut conclue à Vitoria ; mais Fierro, frappé d’une panique soudaine, et sans attendre le retour de ses propres émissaires, décampa secrètement dans la nuit, laissant plus de mille cinq cents Espagnols à la merci de l’ennemi.
Bolívar fut alors honoré d’un triomphe public.
Debout sur un char de triomphe tiré par douze jeunes filles habillées de blanc et décorées aux couleurs nationales, toutes choisies parmi les meilleures familles de Caracas, Bolívar, tête nue, en grand uniforme et tenant un petit bâton à la main, mit environ une demi-heure pour être conduit aux portes de la ville à sa résidence.
Après s’être proclamé « dictateur et libérateur des provinces de l’ouest du Venezuela » (car Mariňo avait pris le titre de « dictateur des provinces de l’est ») ; il choisit un corps de troupe d’élite pour en faire sa garde personnelle et s’entoura de l’éclat d’une Cour.
Mais, comme la plupart de ses compatriotes, il était un ennemi de tout effort prolongé et sa dictature sombra bientôt dans l’anarchie militaire : les affaires les plus importantes étaient aux mains de favoris qui gaspillaient les finances du pays et avaient ensuite recours à des moyens odieux pour les restaurer.
Ainsi, l’enthousiasme tout récent du peuple se transforma en mécontentement, et les forces dispersées de l’ennemi purent se reconstituer.
Au début d’août 1813, Monteverde était enfermé dans la forteresse de Puerto Cabello, et l’armée espagnole ne possédait plus qu’une petite langue de terre au nord-ouest du Venezuela ; trois mois, plus tard, en décembre, le libérateur avait perdu son prestige et Caracas était menacée par l’apparition soudaine dans ses alentours des Espagnols victorieux sous les ordres de Boves.
Pour renforcer son pouvoir chancelant, Bolívar réunit le 1er janvier 1814 une junte des habitants les plus influents de Caracas et déclara refuser de porter plus longtemps le fardeau de la dictature.
Hurtado Mendoza démontra alors dans un long discours la « nécessité de laisser le pouvoir suprême aux mains du général Bolívar jusqu’à ce que le congrès de la Nouvelle-Grenade puisse se tenir et que le Venezuela s’unifie sous l’autorité d’un gouvernement ».
Cette proposition fut acceptée, et la dictature fut ainsi en quelque sorte investie d’une sanction légale.
La guerre contre les Espagnols se poursuivit quelque temps en une série d’engagements où aucun des deux partis n’obtenait un avantage décisif.
En juin 1814, Boves marcha, avec ses forces unifiées, de Calabozo à La Puerta où les deux dictateurs, Bolívar et Mariňo, avaient opéré une jonction, les rencontra et ordonna de les attaquer immédiatement.
Après quelque résistance, Bolívar s’enfuit vers Caracas, tandis que Mariňo disparaissait en direction de Cumana.
Puerto Caballo et Valence tombaient aux mains de Boves, qui détacha alors deux colonnes (dont l’une était commandée par le colonel Gonzales) vers Caracas, par des routes différentes.
Après que Caracas eut capitulé devant Gonzales, le 17 juillet 1814, Bolívar évacua La Guayra, ordonna que les navires se trouvant dans le port de cette ville fassent voile vers Cumana, et battit en retraite sur Barcelone avec le reste de ses troupes.
Après une défaite infligée aux insurgés par Boves à Anguita le 8 août 1814, Bolívar abandonna ses troupes la même nuit pour gagner secrètement, en toute hâte et par des chemins détournés, Cuman où, malgré les protestations et la colère de Rivas, il s’embarqua immédiatement à bord du Bianchi avec Mariňo et quelques autres officiers.
Si Rivas, Páez et d’autres généraux avaient suivi les dictateurs dans leur fuite, tout aurait été perdu.
A leur arrivée à Juan Griego, sur l’île de Margarita, ils furent traités de déserteurs par le général Arismendi, qui leur ordonna de partir ; ils se dirigèrent vers Carupano, où le colonel Bermudez les reçut de la même façon, et mirent le cap sur Carthagène.
Là, pour travestir leur fuite, ils publièrent un mémoire où ils se justifiaient avec des phrases pompeuses.
S’étant mêlé à un complot pour le renversement du gouvernement de Carthagène, Bolívar dut quitter cette petite république, et fit route vers Tunja, où se tenait le congrès de la république fédérale de Nouvelle-Grenade.
A cette époque, la province de Cundinamarca était à la tête de provinces indépendantes qui refusaient l’accord fédéral de Grenade, tandis que Quito, Pasto, Santa Marta et d’autres provinces restaient encore aux mains des Espagnols.
Arrivé à Tunja le 22 novembre 1814, Bolívar fut nommé par le congrès commandant en chef des forces fédéralistes et reçut la double mission de forcer le président de la province de Cundinamarca à reconnaître l’autorité du congrès, puis de marcher contre Santa Marta, seul port fortifié que les Espagnols détenaient encore en Nouvelle-Grenade.
La première tâche fut facilement remplie, car Bogotá, capitale de la province dissidente, était une ville sans défense.
Bien qu’elle ait capitulé, Bolívar autorisa ses troupes à la piller pendant quarante-huit heures.
A Santa Marta, le général espagnol Montalvo, disposant d’une faible garnison de moins de deux cents hommes et d’une forteresse presque impossible à défendre, avait déjà retenu un navire français pour assurer sa propre fuite, tandis que les habitants de la ville firent savoir à Bolívar qu’à son apparition ils ouvriraient les portes et chasseraient la garnison.
Mais, au lieu de s’attaquer aux Espagnols de Santa Marta comme il en avait reçu l’ordre du congrès, il s’abandonna à sa rancune contre Castillo, commandant de Carthagène, et prit sur lui de conduire ses troupes contre cette ville, qui était partie intégrante de la république fédérale.
Battu, il établit son camp sur La Papa, une grande colline, à portée d’obus de Carthagène, et installa une batterie composée d’un seul canon de faible calibre face à une forteresse disposant d’environ quatre-vingts canons.
Puis il transforma le siège en un blocus qui dura jusqu’au début mai, sans autre résultat que celui de réduire son armée, par la désertion et la maladie, de deux mille quatre cents hommes à environ sept cents.
Pendant ce temps, une grande expédition espagnole, partie de Cadix sous les ordres du général Morillo, était arrivée à l’île de Margarita le 25 mars 1815 et avait pu envoyer des renforts à Santa Marta et, peu de temps après, prendre Carthagène même.
Mais, auparavant, Bolívar s’était embarqué le 10 mai 1815 pour la Jamaïque, accompagné d’une douzaine de ses officiers, sur un brick anglais armé.
Arrivé à ce lieu de refuge, il lança à nouveau une proclamation, se prétendant la victime de quelque faction ou ennemi secret, et justifiant sa fuite devant les Espagnols comme une démission de son commandement eu égard à la paix publique.
Durant son séjour de huit mois à Kingston, les généraux qu’il avait laissés au Venezuela, ainsi que le général Arismendi dans l’île de Margarita, tinrent résolument tête aux troupes espagnoles.
Mais Rivas, à qui Bolívar devait sa gloire, ayant été fusillé par les Espagnols après la prise de Maturin, un autre homme le remplaça sur la scène ; il possédait des capacités encore plus grandes, mais comme il ne pouvait, en sa qualité d’étranger, jouer un rôle indépendant dans la révolution sud-américaine, il se décida à agir sous les ordres de Bolívar. C’était Louis Brion.
Pour apporter son aide aux révolutionnaires, il était parti de Londres à Carthagène avec une corvette de vingt-quatre canons ; équipée en grande partie à ses propres frais, elle contenait quatorze mille fusils et une grande quantité de matériel militaire.
Arrivé trop tard pour se rendre utile dans cette région, il se rembarqua pour Cayes, à Haïti, où de nombreux patriotes émigrés s’étaient rendus après la capitulation de Carthagène.
Bolívar, pendant ce temps, était également parti de Kingston pour Port-au-Prince où sur sa promesse de libérer les esclaves, le président de Haïti, Pétion, lui offrit des fournitures importantes pour monter une expédition contre les Espagnols au Venezuela.
A Cayes, il rencontra Brion et les autres émigrés, et, lors d’une réunion générale, se proposa comme chef de la nouvelle expédition, à condition de réunir entre ses mains les pouvoirs civils et militaires jusqu’à la convocation du congrès général.
La majorité s’étant ralliée à sa proposition, l’expédition partit le 16 avril 1816, ayant Bolívar pour commandant et Brion pour amiral.
A Margarita, Bolívar réussit à se concilier Arismendi, qui commanda l’île après avoir refoulé les Espagnols qui n’occupaient qu’un seul point, Pampatar.
Sur la promesse formelle de Bolívar de convoquer un congrès national au Venezuela dès qu’il serait maître du pays, Arismendi réunit une junte dans la cathédrale de la Villa del Norte, et le proclama publiquement commandant en chef des républiques du Venezuela et de la Nouvelle-Grenade.
Le 31 mai 1816, Bolívar débarqua à Carupano, mais n’osa pas empêcher Mariňo et Piar de se séparer de lui et d’engager une guerre contre Cumana de leur propre autorité.
Affaibli par cette séparation, il fit voile, sur le conseil de Brion, vers Ocumare où il arriva le 3 juillet 1816, avec treize navires, dont sept seulement étaient armés.
Ses troupes ne comprenaient que six cent cinquante hommes, mais l’enrôlement de Noirs dont il avait proclamé l’émancipation portait ce nombre à environ huit cents.
A Ocumare, il publia à nouveau une proclamation promettant d’« exterminer les tyrans » et de « convoquer le peuple pour qu’il nomme ses délégués au congrès ».
En avançant dans la direction de Valence, il rencontra, non loin d’Ocumare, le général espagnol Morales à la tête d’environ deux cents soldats et cent miliciens.
Les tirailleurs de Morales ayant dispersé son avant-garde, il perdit, selon le récit d’un témoin oculaire, « toute présence d’esprit, ne dit pas un mot, fit rapidement tourner bride à son cheval, et s’enfuit à toute vitesse vers Ocumare ; il traversa le village au grand galop, sauta de son cheval, se jeta dans une barque et parvint ainsi à bord de la Diana où il ordonna à toute l’escadre de le suivre jusqu’à la petite île de Buen Aire, abandonnant tous ses compagnons sans aide d’aucune sorte ».
Accablé de vifs reproches et de remontrances par Brion, il rejoignit les autres commandants sur la côte de Cumana ; mais, reçu avec rudesse et menacé par Piar d’être jugé devant une cour martiale comme déserteur et comme poltron, il rebroussa vite chemin et revint à Cayes.
Après des mois d’effort, Brion parvint finalement à persuader la majorité des chefs militaires vénézuéliens, qui sentaient le besoin d’avoir au moins un chef nominal, de rappeler Bolívar à son poste de commandant en chef ; en revanche, il s’engageait formellement à convoquer un congrès et à ne pas intervenir dans l’administration civile.
Le 31 décembre 1816, il arriva à Barcelone avec les armes, les munitions et les provisions diverses fournies par Pétion.
Rejoint le 2 janvier 1817 par Arismendi, il proclama le 4 la loi martiale et la réunion de tous les pouvoirs en sa seule personne ; mais cinq jours plus tard, Arismendi ayant été victime d’une embuscade tendue par les Espagnols, le dictateur s’enfuit à Barcelone.
Les troupes s’y rendirent également, et Brion lui envoya des canons aussi bien que des renforts, ce qui lui permit de rassembler un nouveau corps d’armée de mille cent hommes.
Le 15 avril les Espagnols s’emparèrent de la ville de Barcelone, et les troupes des patriotes se replièrent vers la maison de bienfaisance, située en dehors de Barcelone ; ce bâtiment avait été fortifié sur l’ordre de Bolívar, mais il ne pouvait protéger une garnison de mille hommes en cas d’attaque sérieuse.
Bolívar quitta son poste dans la nuit du 5 avril ; il transféra son commandement au colonel Freites, et l’informa qu’il allait chercher des renforts et serait bientôt de retour.
Confiant en cette promesse, Freites déclina une offre de capitulation et, après l’assaut, fut massacré par les Espagnols avec toute la garnison.
Piar, un homme de couleur natif de Curaçao, prépara et réalisa la conquête des provinces de Guyana, tandis que l’amiral Brion appuyait cette entreprise avec ses canonnières.
Le 20 juillet, l’ensemble de ces provinces ayant été évacué par les Espagnols, Piar, Brion, Zea, Mariňo, Arismendi et d’autres réunirent un congrès provincial à Angostura, et mirent à la tête de l’exécutif un triumvirat.
Brion haïssait Piar et il était en outre profondément attaché au succès de Bolívar : il avait misé son importante fortune personnelle sur ce succès et il réussit à le faire nommer membre du triumvirat malgré son absence.
Lorsqu’il apprit cette nouvelle, Bolívar quitta sa retraite et apparut à Angostura ; encouragé par Brion, après avoir dissous le congrès et le triumvirat, il les remplaça pas un « Conseil suprême de la nation » dont il prit la tête ; Brion et Antonio Francisco Zea furent nommés présidents, le premier pour les affaires militaires, le second pour les affaires politiques.
Cependant, Piar, le conquérant de la Guyana, qui autrefois avait menacé de faire passer Bolívar en cour martiale comme déserteur, n’épargnait pas ses sarcasmes contre le « Napoléon de la retraite » ; dès lors, Bolívar mit au point un plan pour s’en défaire.
Sur la fausse accusation d’avoir conspiré contre les Blancs, comploté contre la vie de Bolívar, et aspiré au pouvoir suprême, Piar fut traduit devant un conseil de guerre présidé par Brion, reconnu coupable, condamné à mort et fusillé le 16 octobre 1817.
Sa mort frappa Mariňo de terreur.
Pleinement conscient de sa propre insignifiance une fois qu’il était séparé de Piar, il calomnia publiquement son ami assassiné dans une lettre des plus abjectes, désavoua ses propres tentatives de rivaliser avec le Libérateur, et en appela à l’inépuisable magnanimité de Bolívar.
La conquête de la Guyana par Piar avait complètement retourné la situation en faveur des patriotes ; cette province fournissait à elle seule plus de ressources que les sept autres provinces du Venezuela réunies.
On s’attendait généralement à ce que la campagne, annoncée par Bolívar dans une nouvelle proclamation, aboutît à l’expulsion définitive des Espagnols.
Ce premier bulletin, qui faisait de quelques petits détachements espagnols à la recherche de fourrage se retirant de Calabozo des « armées fuyant devant nos troupes victorieuses », n’était pas de nature à modérer ces espoirs.
Contre environ quatre mille Espagnols dont la jonction n’avait pas encore été effectuée par Morillo, Bolívar rassembla plus de neuf mille hommes, bien armés et bien équipés, et amplement munis de tout ce qui était nécessaire à la guerre.
Néanmoins, vers la fin du mois de mai 1818, il avait perdu environ une douzaine de batailles et toutes les provinces situées au nord de l’Orinico. En effet, Bolívar dispersa ses forces supérieures en nombre, qui furent toujours battues séparément.
Laissant la conduite des opérations à Páez et à ses autres subalternes, il se retira à Angostura. Les défections se multipliaient et tout semblait aller à la dérive et conduire à une défaite totale.
A ce moment des plus critiques, un heureux concours de circonstances retourna une fois de plus la situation.
A Angostura, Bolívar rencontra Santander, originaire de la Nouvelle-Grenade, qui le supplia de lui accorder les moyens d’envahir ce territoire, où la population était prête à déclencher un soulèvement général contre les Espagnols.
Bolívar donna une certaine suite à cette demande, tandis que des secours importants en hommes, en navires et en munitions arrivés d’Angleterre, et que des officiers anglais, français, allemands et polonais affluaient à Angostura.
Enfin, le Dr German Rosci, consterné par la fortune déclinante de la révolution sud-américaine, entra en scène, acquit de l’influence sur Bolívar et le décida à réunir le 15 février 1819, un congrès national, dont la seule annonce se révéla assez forte pour faire surgir une nouvelle armée d’environ quatorze mille hommes, ce qui permit à Bolívar de reprendre l’offensive.
Les officiers étrangers lui suggérèrent de simuler l’intention d’attaquer Caracas et de libérer le Venezuela du joug espagnol ; Morillo serait ainsi amené à retirer ses forces de Nouvelle-Grenade et à les concentrer pour assurer la défense du Venezuela, tandis que Bolívar, se dirigeant soudain vers l’ouest, s’unirait aux guérillas de Santander, et marcherait sur Bogotá.
Pour exécuter ce plan, Bolívar quitta Angostura le 24 février 1819, après avoir nommé Zea président du Congrès et vice-président de la République en son absence.
Grâce aux manœuvres de Páez, Morillo et La Torre furent battus à Achaguas, et ils auraient été anéantis si Bolívar avait opéré une jonction de ses propres troupes avec celles de Páez et Mariňo.
Quoi qu’il en soit, les victoires de Páez conduisirent à l’occupation de la province de Barima, ce qui permettait à Bolívar de pénétrer en Nouvelle-Grenade.
Là, tout avait été préparé par Santander, et les troupes étrangères, composées surtout d’Anglais, décidèrent du sort de la Nouvelle-Grenade par les victoires successives remportées les 1er et 23 juillet et le 7 août, dans la province de Tunja.
Le 12 août, Bolívar fit une entrée triomphale dans Bogotá, tandis que les Espagnols, contre lesquels toutes les provinces de Nouvelle-Grenade s’étaient soulevées, s’enfermaient dans la ville fortifiée de Mompox.
Après avoir ouvert le congrès de la Nouvelle-Grenade à Bogotá et nommé le général Santander au poste de commandant en chef, Bolívar marcha vers Pamolona, où il passa environ deux mois à faire des fêtes et à courir les bals.
Le 3 novembre, il arriva à Montecal, au Venezuela, où il avait ordonné aux chefs patriotiques de ce pays de s’assembler avec leurs troupes.
Il disposait alors d’un trésor d’environ deux millions de dollars, provenant des contributions forcées des habitants de la Nouvelle-Grenade, et d’une armée de quelque neuf mille hommes, dont le tiers était composé d’Anglais, d’Irlandais, d’Hanovriens, et d’autres étrangers, bien disciplinés.
Il put ainsi affronter un ennemi dépourvu de toute ressource et réduit à une force nominale d’environ quatre mille cinq cents hommes, dont les deux tiers étaient des indigènes auxquels les Espagnols ne pouvaient se fier.
Morillo se retirant de San Fernando de Apure vers San Carlos, Bolívar le poursuivit jusqu’à Calabozo, de sorte que les quartiers-généraux ennemis étaient seulement à deux jours de marche l’un de l’autre. Si Bolívar s’était avancé hardiment, les Espagnols auraient été écrasés par les seules troupes européennes ; mais il préféra prolonger la guerre de cinq ans.
En octobre 1819, le Congrès d’Angostura avait forcé Zea, sa créature, à démissionner de son poste et choisi Arismendi à sa place.
Lorsqu’il reçut cette nouvelle, Bolívar fit soudain marcher sa légion étrangère vers Angostura, surprit Arismendi, qui n’avait que six cents indigènes, l’exila dans l’île de Margarita, et réinstalla Zea dans son ancienne dignité.
Le Dr Rosci, qui l’enthousiasma par la perspective d’un pouvoir central, l’amena à proclamer la « République de Colombie » comprenant la Nouvelle-Grenade et le Venezuela, à publier une Constitution pour le nouvel Etat et à consentir à l’établissement d’un congrès commun pour les deux provinces. Le 20 janvier 1820, il retourna de nouveau à San Fernando de Apure.
Le retrait soudain de la légion étrangère, que les Espagnols craignaient plus que le décuple du nombre de troupes colombiennes, avait donné à Morillo une nouvelle occasion de rassembler des renforts, tandis que l’annonce d’une formidable expédition, qui devait partir d’Espagne commandée par O’Donnell, rehaussa le moral en baisse de l’armée espagnole. Malgré la supériorité écrasante de ses forces, Bolívar n’obtint aucun résultat pendant la campagne de 1820.
Entre-temps, on apprit d’Europe que la révolution dans l’Isle de Leon avait mis fin violemment au projet d’expédition de O’Donnell.
En Nouvelle-Grenade, quinze provinces sur vingt-deux s’étaient ralliées au gouvernement de Colombie, et les Espagnols n’y détenaient plus que les forteresses de Carthagène et l’isthme de Panama.
Au Venezuela, six provinces sur huit obéissaient aux lois de Colombie. Telle était la situation lorsque Bolívar se laissa entraîner par Morillo à des négociations qui aboutirent, le 25 novembre 1820, à la conclusion, à Trujillo, d’un armistice de six mois.
Aucune mention n’était faite dans cette trêve de la République de Colombie, bien que le Congrès eût formellement interdit de conclure aucun traité avec le commandement espagnol avant que celui-ci ne reconnaisse l’indépendance de la République.
Le 17 décembre, Morillo, désireux de jouer un rôle en Espagne, fit route vers Puerto Cabello, laissant le commandement en chef à Miguel de La Torre ; le 10 mars 1821, Bolívar écrivit à La Torre que les hostilités reprendraient à l’expiration d’un délai de trente jours.
Les Espagnols avaient pris une position assez solide à Carabozo, village situé à mi-chemin environ de San Carlos et de Valence, mais au lieu d’y réunir toutes ses forces, La Torre y avait seulement concentré sa première division, comprenant deux mille cinq cents fantassins et environ mille cinq cents cavaliers ; Bolívar disposait d’environ six mille fantassins, dont la légion britannique, avec mille cent hommes et trois mille Ilaneros à cheval, sous les ordres de Páez.
Mais la position de l’ennemi lui paraissait si imprenable qu’il proposa à son conseil de guerre de conclure un nouvel armistice, ce qui fut toutefois rejeté par les subalternes.
A la tête d’une colonne composée principalement de la légion britannique, Páez réussit à contourner, par un sentier, l’aile droite de l’ennemi ; La Torre fut le premier parmi les Espagnols à s’enfuir, ne prenant aucun répit avant d’atteindre Puerto Cabello, où il s’enferma avec le reste de ses troupes.
Puerto Cabello se serait rendue sans condition si l’armée victorieuse s’était avancée rapidement, mais Bolívar perdit son temps en s’exhibant à Valence et à Caracas. Le 21 septembre 1821, la puissante forteresse de Carthagène capitulait devant Santander.
Les derniers faits d’armes au Venezuela – l’engagement naval de Maracaibo en août 1923 et la capitulation forcée de Puerto Cabello en juillet 1824 – furent tous deux l’œuvre de Padilla.
La révolution de l’Isle de Leon, qui empêcha le départ de l’expédition de O’Donnell, et le concours de la légion britannique avaient évidemment fait pencher la balance en faveur des Colombiens.
La session du Congrès colombien s’ouvrit à Cucuta en janvier 1821 ; le Congrès publia le 30 août une nouvelle constitution et confirma dans ses pouvoirs Bolívar qui, une fois de plus, avait menacé de démissionner.
Après avoir signé la constitution, il obtint l’autorisation d’entreprendre la campagne de Quito (1822), province où les Espagnols s’étaient retirés après avoir été repoussés de l’isthme de Panama par un soulèvement populaire général.
Cette campagne, qui se termina par l’incorporation de Quito, Posto et Guayaquil à la Colombie, fut dirigée nominalement par Bolívar et le général Sucre, mais les quelques succès de l’armée furent entièrement dus aux officiers britanniques, tel le colonel Sands.
Durant les campagnes de 1823-1824 contre les Espagnols dans le haut et le bas Pérou, Bolívar n’estima plus nécessaire de conserver les apparences du commandement ; au contraire, il abandonna toute la direction militaire au général Sucre, se consacrant lui-même exclusivement à des entrées triomphales, à des manifestes et à la proclamation de constitutions.
A l’aide de sa garde personnelle colombienne, il pesa sur les décisions du Congrès de Lima qui lui transféra, le 10 février 1823, les pouvoirs de dictateur, tandis qu’il assurait sa réélection à la présidence de Colombie par une nouvelle manœuvre de démission.
Entre-temps, sa position s’était renforcée, tant par la suite de la reconnaissance formelle du nouvel Etat par l’Angleterre que grâce à la conquête, par Sucre, des provinces du haut Pérou, que ce dernier unifia en une République indépendante sous le nom de Bolivie.
Dans ce pays, où les baïonnettes de Sucre détenaient le pouvoir suprême, Bolívar donna libre cours à ses penchants pour le pouvoir arbitraire, en introduisant le Code Boliviano, imitation du Code Napoléon.
Son plan consistait à exporter ce Code de la Bolivie au Pérou et du Pérou à la Colombie, tout en gardant le contrôle des deux premiers Etats par des troupes colombiennes, et du dernier par la légion étrangère et des soldats péruviens.
Par la force et par l’intrigue, il réussit effectivement, au moins pour quelques semaines, à imposer son Code au Pérou.
Président et Libérateur de la Colombie, protecteur et dictateur du Pérou et parrain de la Bolivie, il était alors à l’apogée de sa gloire.
Mais de graves différends avaient éclaté en Bolivie entre les centristes ou Bolívaristes et les fédéralistes ; sous ce nom, les ennemis de l’anarchie militaire s’étaient ralliés aux rivaux de Bolívar dans l’armée.
Le Congrès colombien ayant à son instigation dressé un acte d’accusation contre Páez, vice-président du Venezuela, ce dernier riposta par une révolte ouverte, secrètement soutenue et alimentée par Bolívar lui-même, qui désirait des insurrections afin d’avoir un prétexte de renverser la constitution et ressaisir la dictature.
A son retour du Pérou, outre sa garde personnelle, il s’était attaché mille huit cents Péruviens qu’il déclarait conduire contre les rebelles fédéralistes.
A Puerto Cabello, où il rencontra Páez, non seulement il le confirma dans son commandement au Venezuela, mais il prit ouvertement sa défense et blâma les amis de la constitution ; par le décret de Bogotá, le 23 novembre 1826, il assuma les pouvoirs dictatoriaux.
En 1827, début du déclin de son pouvoir, il parvint à réunir un congrès à Panama, dont le but officiel fut d’établir un nouveau Code international démocratique.
Des délégués vinrent de Colombie, du Brésil, de La Plata, de Bolivie, de Mexico, du Guatémala, etc.
Son intention réelle était de transformer toute l’Amérique du Sud en une république fédérative soumise à sa dictature.
Tandis qu’il lâchait ainsi la bride à son rêve d’attacher la moitié du monde à son nom, le pouvoir réel échappait rapidement à son emprise.
Les troupes colombiennes du Pérou, informées des mesures qu’il prenait pour introduire le Code Boliviano, déclenchèrent une insurrection armée.
Les Péruviens élurent le général La Mar président de leur République, aidèrent les Boliviens à chasser les troupes colombiennes de leur sol et engagèrent une guerre victorieuse contre la Colombie ; un traité réduisit cette dernière à ses limites primitives, stipulant l’égalité des deux pays et séparant leurs dettes publiques.
Le Congrès d’Ocana, convoqué par Bolívar en vue de modifier la constitution en faveur de son pouvoir absolu, fut ouvert le 2 mars 1828 par un message soigneusement élaboré qui insistait sur la nécessité d’octroyer de nouveaux privilèges à l’exécutif.
Cependant, lorsqu’il devint évident que le projet de constitution amendé sortirait du Congrès très différent de sa forme originale, ses amis quittèrent leurs sièges : l’assemblée n’atteignit pas le quorum, ce qui mit fin à son activité.
D’une maison de campagne à quelques kilomètres d’Ocana, où il s’était retiré, Bolívar publia un nouveau manifeste ; il se prétendait irrité par l’attitude de ses propres amis, mais il attaquait en même temps le Congrès, appelant les provinces à recourir à des mesures exceptionnelles et se déclarant prêt à assumer tout pouvoir qui lui serait confié.
Sous la pression de ses baïonnettes, des assemblées populaires à Caracas, Carthagène et Bogotá, où il s’était rendu, l’investirent à nouveau de pouvoirs dictatoriaux.
Il faillit être assassiné à Bogotá, dans sa chambre, et échappa à la mort en sautant du balcon pour se cacher et se réfugier sous un pont ; cet assassinat manqué lui permit d’exercer pendant un temps une sorte de terrorisme militaire.
Toutefois, il ne toucha pas à la vie de Santander, bien que celui-ci eût participé à la conspiration ; en revanche, il fit mettre à mort le général Padilla, dont la culpabilité n’était pas du tout prouvée, mais qui, en tant qu’homme de couleur, ne pouvait se défendre.
En 1829, une violente lutte de factions secoua la République ; dans un nouvel appel, Bolívar invita les citoyens à exprimer franchement leurs désirs quant aux modifications à introduire dans la constitution.
Une assemblée de notables à Caracas répondit en dénonçant son ambition, en proclamant la séparation du Venezuela de la Colombie et en plaçant Páez à la tête de cette République.
Le Sénat de Colombie soutint Bolívar, mais d’autres insurrections éclatèrent en différents endroits.
Après avoir démissionné pour la cinquième fois en janvier 1830, il accepta une fois de plus la présidence, et quitta Bogotá pour mener campagne contre Páez, au nom du Congrès colombien.
Vers la fin de mars 1830, il s’avança à la tête de huit mille hommes, prit Caracuta qui s’était révolté, puis se tourna vers la province de Maracaibo où Páez l’attendait avec douze mille hommes sur de solides positions.
Dès qu’il comprit que Páez avait l’intention de se battre sérieusement, son courage l’abandonna. Pour un temps, il pensa même à se soumettre à Páez, et se retourner contre le Congrès.
Mais l’influence de ses partisans au Congrès s’affaiblit et il dut offrir sa démission : on lui avait fait savoir qu’il devrait cette fois respecter sa décision et qu’une pension annuelle lui serait accordée s’il partait à l’étranger. Il envoya donc le 27 avril 1830 sa démission au Congrès.
Mais il n’avait pas perdu l’espoir de regagner le pouvoir grâce à l’influence de ses partisans, et, comme une réaction se produisit contre Joaquim Mosquera, nouveau président de la Colombie, il fit traîner son départ de Bogotá, et parvint sous divers prétextes à prolonger son séjour à San Pedro jusqu’à la fin de 1830, où il mourut subitement.
Voici le portrait que donne de lui Ducoudrey-Holstein : « Simón Bolívar mesure cinq pieds six pouces, son visage est long, ses joues creuses, son teint olivâtre ; il a des yeux assez grands et enfoncés dans leurs orbites, une chevelure peu fournie.
Ses moustaches lui donnent un air sombre et sauvage, surtout lorsqu’il est en colère.
Tout son corps est mince et maigre. Il ressemble à un homme de soixante-cinq ans.
Lorsqu’il se déplace, ses bras sont sans cesse en mouvement. Il ne peut pas marcher longtemps et se fatigue vite. Il adore s’asseoir ou s’allonger dans son hamac.
Il se laisse aller à des accès de furie et ce sont presque des crises de folie ; il se jette dans son hamac, profère des jurons et des imprécations contre tous ceux qui l’entourent.
Il aime se répandre en sarcasmes sur les personnes absentes, ne lit que de la littérature française facile, est un hardi cavalier et se passionne pour la valse. Il s’écoute volontiers parler et porter des toasts.
Dans l’adversité, s’il est privé d’aide extérieure, il se libère parfaitement de toute passion et de tout éclat d’humeur. Il devient alors doux, patient, docile et même humble.
Il dissimule admirablement ses défauts sous la politesse d’un homme éduqué dans le soi-disant beau monde (en fr.), possède un talent de dissimulation quasi asiatique et fait preuve d’une meilleure compréhension des hommes que la plupart de ses compatriotes ».
Par décret du Congrès de la Nouvelle-Grenade ses restes furent transportés en 1842 à Caracas où fut érigé un monument en son honneur.
Voir Histoire de Bolívar par le général Ducoudrey-Holstein, continué jusqu’à sa mort par Alphonse Viollet (Paris, 1831) ; Memoirs of General John Willer (in the service of the Republic of Peru) ; colonel Hippisley, Account of his Journey to the Orinoco (London, 1919).
K. Marx, 8 janvier 1858
->retour au dossier
L’idéologie latino-américaine (Ariel, Caliban, Gonzalo)